- Website SEO Marketing
- Blog
- SEO
- Robots.txt Nedir?
Robots.txt Nedir?

Robots.txt, Türkçe de “Robot Engelleme Standardı” olarak bilinmektedir, bir metin dosyasıdır. Bu metin dosyasının amacı arama motoru tarayıcıları için talimat vermektir bu sayede web sitesi tarayıcılarının hangi alanlarında arama yapacağını tanımlar. Bununla birlikte, Robots.txt bu izinli alanları açıkça belirtmez- adlandırmaz bunun yerine belirli alanlarda arama yapılmasını engeller ya da diğer bir deyişle izin vermez. Robot.txt dosyalarınızda komut oluşturabilirsiniz, bu sayede arama motorları sizin komutlarınıza uygun olarak arattığınız kelime ya da kelime öbeklerine uygun sonuçları karşınıza çıkarır. Robots.txt günümüzde önemli ve büyük arama motoru şirketlerinin takip ettiği bir sistemdir ancak hala takip etmeyen arama motoru sistemleri de bulunmaktadır. Bu sebeple en büyük arama motorlarından olan Google, robots.txt dosya yönlendirmelerine ek olarak her zaman için sayfa kaynak kodlarından meta robots işaretlemelerinin kullanılmasını önermektedir. Kullanım amacı web sitelerini sınıflandırmak ve arşivlemektir arama motorları ya da düzeltilmiş kaynak kodları için site yöneticileri robotları kullanırlar. Robotlar bu işlem sonucunda web siteleri için site haritaları oluştururlar.
Robots.txt, bir etki alanının kök dizininde depolanmaktadır. Bu sebeple, sitenizi ziyaret ederken tarayıcıların açtığı ilk belgedir. Robotlar, Robots.txt ile yapmış oldukları işlemin sonucunda web siteleri için site haritaları oluştururlar.
Robot.txt Nasıl Çalışır?
1994 yılında REP (Robots Exclusion Standard Protocol) isimli bir protokol yayımlanmıştır. Bu protokol, tüm arama motoru tarayıcılarının (kullanıcı aracıları) önce sitenizin kök dizininde robots.txt dosyasını aramasını ve içerdiği talimatları okumasını şart koşmaktadır.
Dosya doğrudan etki alanınızın kök dizininde bulunmalıdır ve robotlar robots.txt dosyasını ve talimatlarını büyük/küçük harfe duyarlı olarak okuduğundan küçük harfle yazılması gerekir. Ne yazık ki, tüm arama motoru robotları bu kurallara uymamakta ancak Bing, Yahoo ve Google gibi büyük ve en önemli arama motorları robot.txt ile çalışmaktadır. Bu şirketlerin arama robotları, REP ve robots.txt talimatlarını kesinlikle takip etmektedirler. Pratikte, robots.txt farklı dosya türleri için kullanılabilir, mesela, resim dosyaları için kullanırsanız, bu dosyaların Google arama sonuçlarında görünmesini engeller. Komut dosyası, stil ve görüntü dosyaları gibi önemsiz kaynak dosyaları da robots.txt ile kolayca engellenebilir. Ayrıca, uygun komutları kullanarak dinamik olarak oluşturulmuş web sayfalarının taranmasını da engelleyebilirsiniz. Örneğin, herhangi bir arama işlevinin sonuç sayfaları, oturum kimlikleri olan sayfalar veya alışveriş sepetleri gibi kullanıcı işlemleri engellenebilir. Metin dosyasını kullanarak diğer resim olmayan dosyalara (web sayfaları) tarayıcı erişimini de kontrol edebilirsiniz.
Robots.txt Dosyasında Hangi Talimatlar Kullanılır?
Bir robots.txt dosyasında aşağıdaki terimler kullanılır:
- User-agent: tarayıcının adını belirtir (adlar Robots Veri tabanında bulunabilir)
- İzin verme: belirli dosyaların, dizinlerin veya web sayfalarının taranmasını önler
- İzin ver: üzerine yazar izin vermeme ve dosyaların, web sayfalarının ve dizinlerin taranmasına izin verir
- Site haritası (isteğe bağlı): site haritasının konumunu gösterir
- *: herhangi bir sayıda karakter anlamına gelir
- $: satırın sonu anlamına gelir
Robots.txt dosyasındaki talimatlar (girişler) her zaman iki bölümden oluşur.
İlk bölümde, komutun hangi robotlar (kullanıcı aracıları) için geçerli olduğunu tanımlarsınız. İkinci kısım İSE talimatı içerir (izin verme veya izin verme).
"user-agent: Google-Bot" ve "disallow: /clients/" talimatı, Google botunun /clients/ dizininde arama yapmasına izin verilmediği anlamına gelir.
Tüm web sitesi bir arama botu tarafından taranmayacaksa, giriş: "user-agent: *" ve "disallow: /" talimatıdır.
Belirli bir uzantıya sahip web sayfalarını engellemek için dolar işaretini "$" kullanabilirsiniz.
Bununla birlikte, "disallow: /* .doc$" ifadesi, .doc uzantılı tüm URL'leri engeller. Aynı şekilde, robots.txt: "disallow: /*.jpg$" dosyasında belirli dosya biçimlerini engelleyebilirsiniz.
ÖRNEK KULLANIMLAR[1]
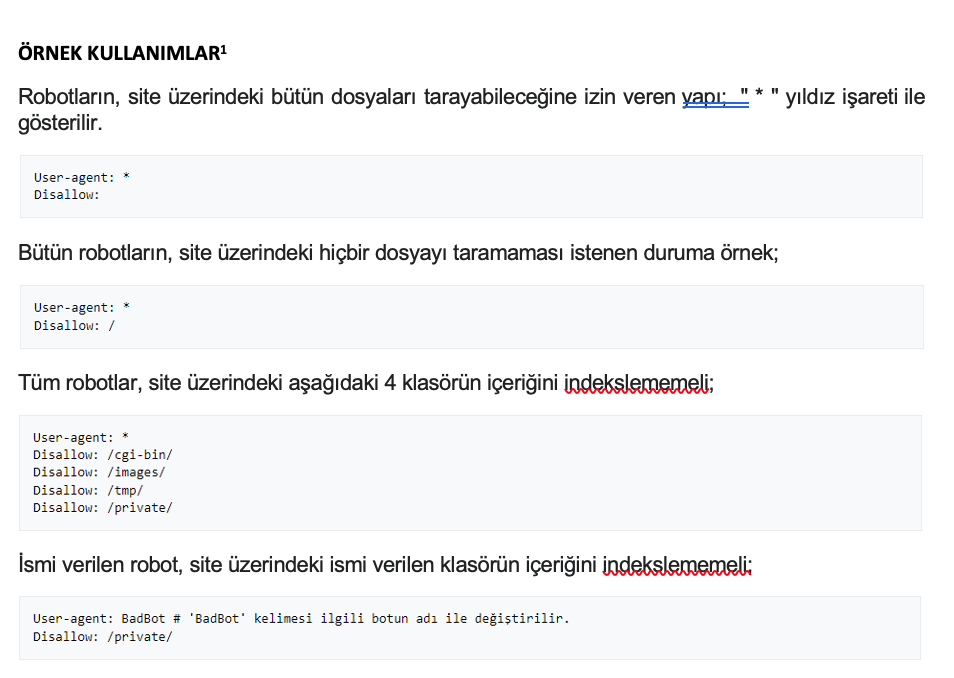
Robotların, site üzerindeki bütün dosyaları tarayabileceğine izin veren yapı; " * " yıldız işareti ile gösterilir.
Bütün robotların, site üzerindeki hiçbir dosyayı taramaması istenen duruma örnek;
Tüm robotlar, site üzerindeki aşağıdaki 4 klasörün içeriğini indekslememeli;
İsmi verilen robot, site üzerindeki ismi verilen klasörün içeriğini indekslememeli;


 Türkçe
Türkçe 
Copyright © 2024